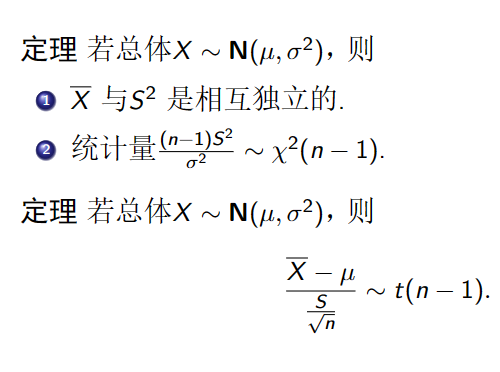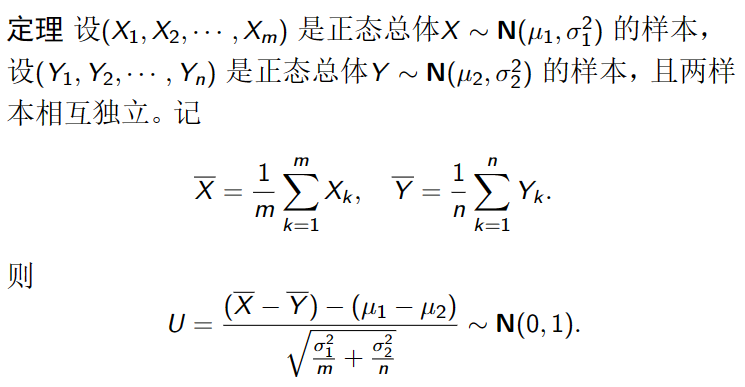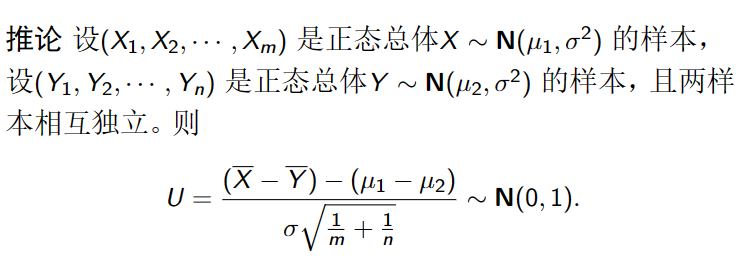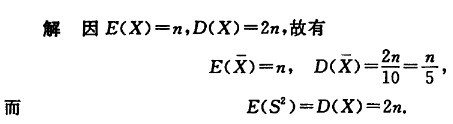WHU特供概率论第六章复习材料
数理统计
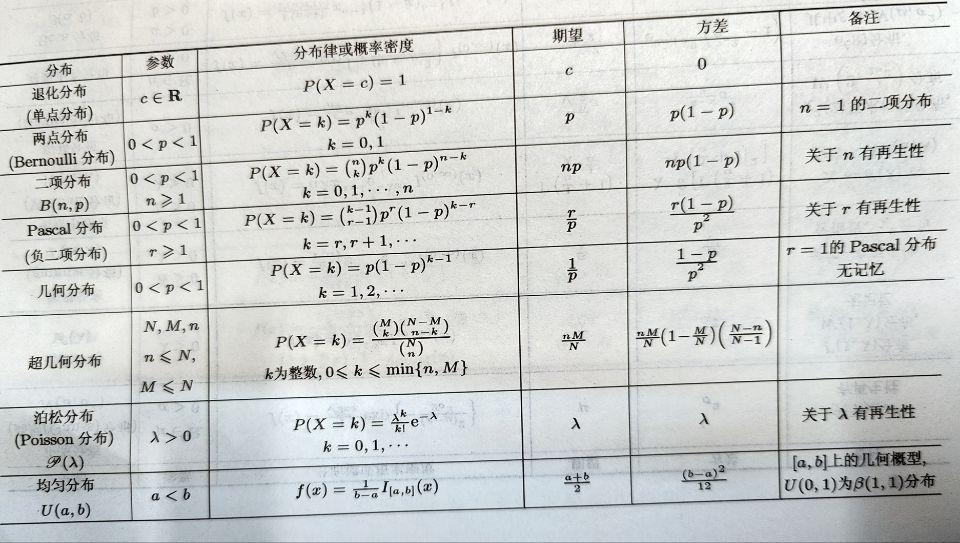
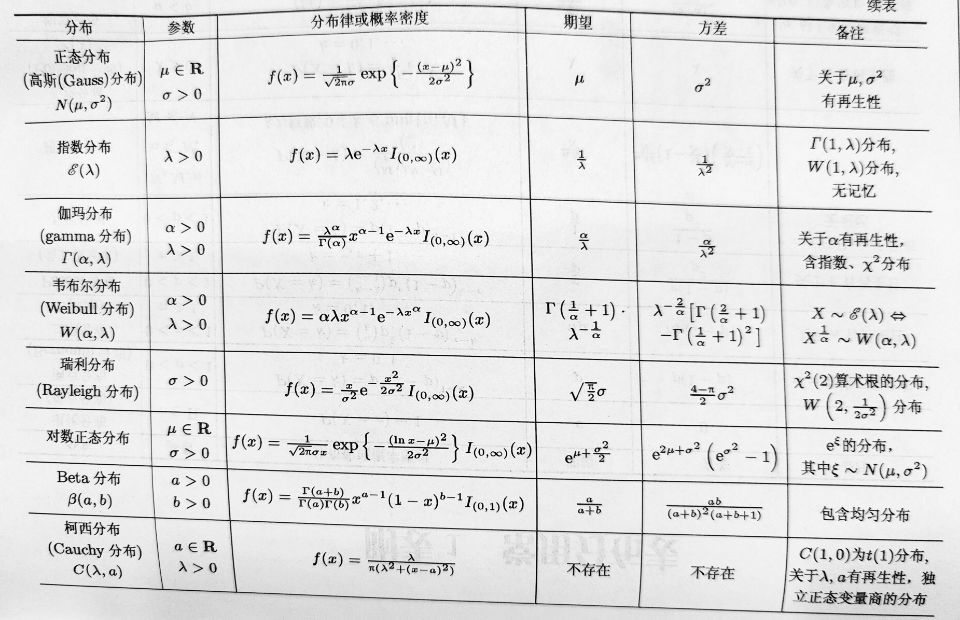
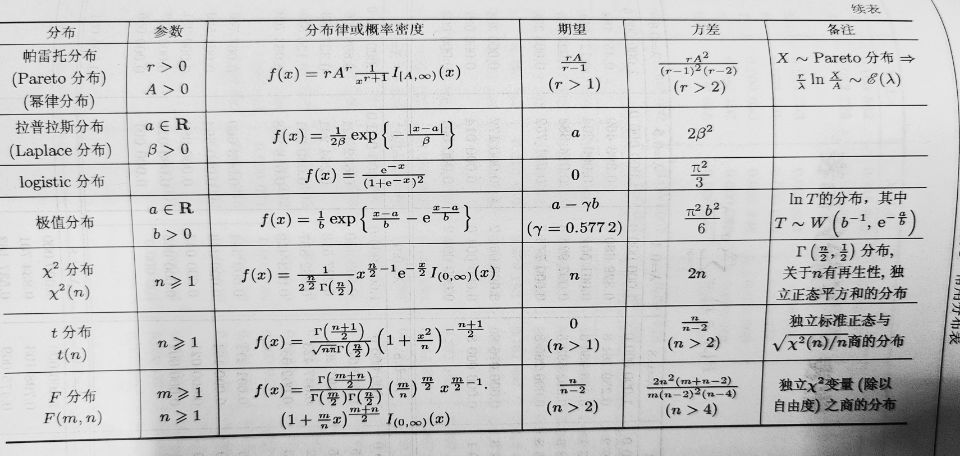
P149:4,6,7
总体与样本
定义 被研究的对象的全体称为总体个体数量指标以及该指标在总体中的概率分布情况。
所谓总体,就是一个具有确定分布的随机变量。用随机变量X 或其分布函数F(x) 来表征总体,记作“总体X或“总体F(x)”总体X 的分布函数F(x) 在一般情况下是未知的,统计推断的任务就是确定总体的分布往往从总体中抽取一部分个体进行试验,通过试验获取定的数据,然后再利用这些数据来分析推断总体F(x)的具体分布形式。
定义 设(Xi,X,…,X) 是n 维随机变量,若X1,X,…,X,是相互独立的且与总体X 具有相同的分布,则称(Xi,X2,.·,X)是取自总体X 的容量为n 的简单随机样本,简称为样本样本观察值或样本值。
统计量与抽样分布
定义 设(X1,X2,…,X,) 是来自总体的样本,g(xi,x2,…)是x1,x2,.·,xn 的连续函数,若g 不含任何未知参数,则称g(Xi,X2,…,X) 是统计量; 若(xi,2,…,x) 是样本观察值,则称g(xi,x,…·,x) 是该统计量的观察值
一些定义
若假设X 1 , X 2 , ⋯ , X n 是来自总体 X 的样本, x 1 , x 2 , ⋯ , x n 为样本观察值 X_1,X_2,\cdots,X_n是来自总体X的样本,x_1,x_2,\cdots,x_n为样本观察值 X 1 , X 2 , ⋯ , X n 是来自总体 X 的样本, x 1 , x 2 , ⋯ , x n 为样本观察值
X ‾ = 1 n ∑ i = 1 n X i \overline{X}=\frac1n\sum_{i=1}^nX_i X = n 1 ∑ i = 1 n X i S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ‾ ) 2 = 1 n − 1 ( ∑ i = 1 n X i 2 − n X ‾ 2 ) S^2=\frac1{n-1}\sum_{i=1}^n(X_i-\overline{X})^2=\frac1{n-1}\left(\sum_{i=1}^nX_i^2-n\overline{X}^2\right) S 2 = n − 1 1 ∑ i = 1 n ( X i − X ) 2 = n − 1 1 ( ∑ i = 1 n X i 2 − n X 2 ) S = S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ‾ ) 2 S=\sqrt{S^2}=\sqrt{\frac1{n-1}\sum_{i=1}^n(X_i-\overline{X})^2} S = S 2 = n − 1 1 ∑ i = 1 n ( X i − X ) 2 A k = 1 n ∑ i = 1 n X i k , k = 1 , 2 , ⋯ A_k=\frac1n\sum_{i=1}^nX_i^k,\quad k=1,2,\cdots A k = n 1 ∑ i = 1 n X i k , k = 1 , 2 , ⋯ B k = 1 n ∑ i = 1 n ( X i − X ‾ ) k , k = 1 , 2 , ⋯ B_k=\frac1n\sum_{i=1}^n(X_i-\overline{X})^k,\quad k=1,2,\cdots B k = n 1 ∑ i = 1 n ( X i − X ) k , k = 1 , 2 , ⋯
上述统计量的观察值分别为x ‾ = 1 n ∑ i = 1 n x i , s 2 = 1 n − 1 ∑ i = 1 n ( x i − x ‾ ) 2 , s = s 2 = 1 n − 1 ∑ i = 1 n ( x i − x ‾ ) 2 , a k = 1 n ∑ i = 1 n x i k , b k = 1 n ∑ i = 1 n ( x i − x ‾ ) k , k = 1 , 2 , ⋯
\begin{gathered}
\overline{x}=\frac1n\sum_{i=1}^nx_i,~s^2=\frac1{n-1}\sum_{i=1}^n(x_i-\overline{x})^2, \\
s=\sqrt{s^2}=\sqrt{\frac1{n-1}\sum_{i=1}^n(x_i-\overline{x})^2}, \\
a_k=\frac1n\sum_{i=1}^nx_i^k,\quad b_k=\frac1n\sum_{i=1}^n(x_i-\overline{x})^k,\quad k=1,2,\cdots
\end{gathered}
x = n 1 i = 1 ∑ n x i , s 2 = n − 1 1 i = 1 ∑ n ( x i − x ) 2 , s = s 2 = n − 1 1 i = 1 ∑ n ( x i − x ) 2 , a k = n 1 i = 1 ∑ n x i k , b k = n 1 i = 1 ∑ n ( x i − x ) k , k = 1 , 2 , ⋯
定理
设总体x x x E X = μ , D ( X ) = σ 2 .
\mathsf{E}X=\mu,\quad\mathsf{D}(X)=\sigma^2.
E X = μ , D ( X ) = σ 2 . ( X 1 , X 2 , ⋯ , X n ) (X_1,X_2,\cdots,X_n) ( X 1 , X 2 , ⋯ , X n ) E ( X ‾ ) = μ , D ( X ‾ ) = σ 2 n , E ( S 2 ) = σ 2 .
\mathbb{E}(\overline{X})=\mu,\quad\mathbb{D}(\overline{X})=\frac{\sigma^2}n,\quad\mathbb{E}(S^2)=\sigma^2.
E ( X ) = μ , D ( X ) = n σ 2 , E ( S 2 ) = σ 2 .
几个分布
统计量的分布称为抽样分布。在总体分布已知时,有时需要 一般情况下,确定统计量的分布是较困难的。但是当总体X 服从正态分布时,可求出x ‾ , S 2 \overline{x},S^2 x , S 2
x 2 x^2 x 2 定义 设随机变量x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x 1 , x 2 , ⋯ , x n
χ 2 = X 1 2 + X 2 2 + ⋯ + X n 2
\chi^2=X_1^2+X_2^2+\cdots+X_n^2
χ 2 = X 1 2 + X 2 2 + ⋯ + X n 2 χ 2 \chi^2 χ 2 χ 2 ∼ χ 2 ( n ) \chi^2\sim\chi^2(n) χ 2 ∼ χ 2 ( n ) χ 2 ( n ) \chi^2(n) χ 2 ( n )
f ( x ) = { 1 2 n 2 Γ ( n 2 ) x n 2 − 1 e − x 2 , 当 x > 0 , 0 , 当 x ≤ 0.
\left.f(x)=\left\{\begin{array}{ll}\frac1{2^{\frac n2}\Gamma\left(\frac n2\right)}x^{\frac n2-1}e^{-\frac x2},&\text{当}\quad x>0,\\0,&\text{当}\quad x\leq0.\end{array}\right.\right.
f ( x ) = { 2 2 n Γ ( 2 n ) 1 x 2 n − 1 e − 2 x , 0 , 当 x > 0 , 当 x ≤ 0. χ 2 \chi^2 χ 2 ξ 1 ∼ χ 2 ( n 1 ) , ξ 2 ∼ χ 2 ( n 2 ) \xi_1\sim\chi^2(n_1),\xi_2\sim\chi^2(n_2) ξ 1 ∼ χ 2 ( n 1 ) , ξ 2 ∼ χ 2 ( n 2 ) ξ 1 \xi_1 ξ 1 ξ 2 \xi_2 ξ 2 ξ 1 + ξ 2 ∼ χ 2 ( n 1 + n 2 ) \xi_1+\xi_2\sim\chi^2(n_1+n_2) ξ 1 + ξ 2 ∼ χ 2 ( n 1 + n 2 )
小结论
对x i x_i x i E ( χ 2 ) = n , D ( χ 2 ) = 2 n E(\chi ^2) = n, D(\chi ^2) = 2n E ( χ 2 ) = n , D ( χ 2 ) = 2 n 若 X i ∼ N ( 0 , 1 ) X 1 + X 2 + X 3 ∼ N ( 0 , 3 )
若X_i \sim N(0,1) \\
X_1 + X_2 + X_3 \sim N(0,3)
若 X i ∼ N ( 0 , 1 ) X 1 + X 2 + X 3 ∼ N ( 0 , 3 ) N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) X 1 , X 2 … X n X_1,X_2\dots X_n X 1 , X 2 … X n ∑ E X i 2 = n μ 2 + n σ 2 \sum EX^2_i = n\mu ^2 + n\sigma ^2 ∑ E X i 2 = n μ 2 + n σ 2
例题
(1)设样本X 1 , X 2 , . . . , X X_1,X_2,...,X X 1 , X 2 , ... , X N ( 0 , 1 ) , Y = ( X 1 + X 2 + X 3 ) 2 + N(0,1),Y=(X_1+X_2+X_3)^2+ N ( 0 , 1 ) , Y = ( X 1 + X 2 + X 3 ) 2 + ( X 4 + X 5 + X 6 ) 2 (X_{4}+X_{5}+X_{6})^{2} ( X 4 + X 5 + X 6 ) 2 C C C C Y CY C Y x 2 x^{2} x 2 X 1 , X 2 , . . . , X 6 X_1,X_2,...,X_6 X 1 , X 2 , ... , X 6 x 1 + x 2 + x 3 \mathbf{x} _1+ \mathbf{x} _2+ \mathbf{x} _3 x 1 + x 2 + x 3 ( 0 , 3 ) , x 4 + x 5 + x 6 ( 0, 3) , \quad \mathbf{x} _4+ \mathbf{x} _5+ \mathbf{x} _6 ( 0 , 3 ) , x 4 + x 5 + x 6 x 1 + x 2 + x 3 3 ∼ N ( 0 , 1 ) , x 4 + x 5 + x 6 3 ∼ N ( 0 , 1 ) \frac{x_{1}+x_{2}+x_{3}}{\sqrt{3}}\sim N(0,1),\quad\frac{x_{4}+x_{5}+x_{6}}{\sqrt{3}}\sim N(0,1) 3 x 1 + x 2 + x 3 ∼ N ( 0 , 1 ) , 3 x 4 + x 5 + x 6 ∼ N ( 0 , 1 ) χ 2 \chi^{2} χ 2 ( X 1 + X 2 + X 3 ) 2 3 + ( X 4 + X 5 + X 6 ) 2 3 ∼ χ 2 ( 2 ) ,
\frac{(X_{1}+X_{2}+X_{3})^{2}}{3}+\frac{(X_{4}+X_{5}+X_{6})^{2}}{3}{\sim}\chi^{2}(2)\:,
3 ( X 1 + X 2 + X 3 ) 2 + 3 ( X 4 + X 5 + X 6 ) 2 ∼ χ 2 ( 2 ) ,
即1 3 Y ∼ ˙ χ 2 ( 2 ) \frac{1}{3}Y\dot{\sim}\chi^{2}(2) 3 1 Y ∼ ˙ χ 2 ( 2 ) C = 1 3 . C=\frac{1}{3}. C = 3 1 .
t分布
定义 设X ∼ N ( 0 , 1 ) , Y ∼ χ 2 ( n ) X\sim\mathbf{N}(0,1),Y\sim\chi^2(n) X ∼ N ( 0 , 1 ) , Y ∼ χ 2 ( n ) x x x T = x Y n T=\frac x{\sqrt{\frac Yn}} T = n Y x t t t T ∼ t ( n ) T\sim t(n) T ∼ t ( n )
例题
X 1 , X 2 , . . . , X s X_1,X_2,...,X_s X 1 , X 2 , ... , X s X 1 + X 2 ∼ N ( 0 , 2 ) X_1+X_2\sim N(0,2) X 1 + X 2 ∼ N ( 0 , 2 )
X 1 + X 2 2 ∼ N ( 0 , 1 ) .
\frac{X_{1}+X_{2}}{\sqrt{2}}{\sim}N(0,1).
2 X 1 + X 2 ∼ N ( 0 , 1 ) .
而
X 3 2 + X 4 2 + X 5 2 ∼ χ 2 ( 3 ) .
X_{3}^{2}+X_{4}^{2}+X_{5}^{2}\sim\chi^{2}(3).
X 3 2 + X 4 2 + X 5 2 ∼ χ 2 ( 3 ) .
且X 1 + X 2 2 \frac{X_1+X_2}{\sqrt{2}} 2 X 1 + X 2 X 3 2 + X 4 2 + X 5 2 X_3^2+X_4^2+X_5^2 X 3 2 + X 4 2 + X 5 2
( X 1 + X 2 ) / 2 ( X 3 2 + X 4 2 + X 5 2 ) / 3 = 3 2 X 1 + X 2 ( X 3 2 + X 4 2 + X 5 2 ) 1 / 2 ∼ t ( 3 ) \frac{(X_1+X_2)/\sqrt{2}}{\sqrt{(X_3^2+X_4^2+X_5^2)/3}}=\sqrt{\frac32}\frac{X_1+X_2}{(X_3^2+X_4^2+X_5^2)^{1/2}}\sim t(3) ( X 3 2 + X 4 2 + X 5 2 ) /3 ( X 1 + X 2 ) / 2 = 2 3 ( X 3 2 + X 4 2 + X 5 2 ) 1/2 X 1 + X 2 ∼ t ( 3 )
因此所求的常数C = 3 2 . C=\sqrt{\frac{3}{2}}. C = 2 3 .
F分布
定义 设随机变量X ∼ χ 2 ( n 1 ) , Y ∼ χ 2 ( n 2 ) X\sim\chi^2(n_1),Y\sim\chi^2(n_2) X ∼ χ 2 ( n 1 ) , Y ∼ χ 2 ( n 2 ) x x x F = X n 1 Y n 2
F=\frac{\frac X{n_1}}{\frac Y{n_2}}
F = n 2 Y n 1 X n 1 , n 2 n_1,n_2 n 1 , n 2 F ∼ F ( n 1 , n 2 ) F\sim F(n_1,n_2) F ∼ F ( n 1 , n 2 )
若 F ∼ F ( n 1 , n 2 ) , 则 1 F ∼ F ( n 2 , n 1 ) \text{若}F\sim F(n_1,n_2),\:\text{则}\frac1F\sim F(n_2,n_1) 若 F ∼ F ( n 1 , n 2 ) , 则 F 1 ∼ F ( n 2 , n 1 ) T ∼ t ( n ) T\sim t(n) T ∼ t ( n ) T 2 ∼ F ( 1 , n ) T^2\sim F(1,n) T 2 ∼ F ( 1 , n ) E ( F ( n 1 , n 2 ) ) = n 2 n 2 − 2 E(F(n_1,n_2)) = \frac {n_2} {n_2 - 2} E ( F ( n 1 , n 2 )) = n 2 − 2 n 2
例题
(3) 已知总体 X ∼ t ( n ) X\sim t(n) X ∼ t ( n ) X 2 ∼ F ( 1 , n ) . X^2{\sim}F(1,n). X 2 ∼ F ( 1 , n ) . X ∼ t ( n ) X\sim t(n) X ∼ t ( n ) X X X x = Z Y / n \mathbf{x}=\frac{Z}{\sqrt{Y/n}} x = Y / n Z Y ∼ χ 2 ( n ) , Z ∼ N ( 0 , 1 ) Y{\sim}\chi^2(n),Z{\sim}N(0,1) Y ∼ χ 2 ( n ) , Z ∼ N ( 0 , 1 ) Z Z Z Y Y Y x z = Z 2 Y / n . x^{z}=\frac{Z^{2}}{Y/n}. x z = Y / n Z 2 . Z ∼ N ( 0 , 1 ) , Z ∼ χ 2 ( 1 ) Z{\sim}N(0,1),Z{\sim}\chi^2(1) Z ∼ N ( 0 , 1 ) , Z ∼ χ 2 ( 1 ) Z 2 ∼ χ 2 ( 1 ) Z^2{\sim}\chi^2(1) Z 2 ∼ χ 2 ( 1 ) Y ∼ χ 2 ( n ) Y{\sim}\chi^2(n) Y ∼ χ 2 ( n ) Z Z Z Z 2 Z^2 Z 2 Y Y Y F F F
X 2 ∼ F ( 1 , n ) . X^2{\sim}F(1,n). X 2 ∼ F ( 1 , n ) .
正太总体,X ∼ N ( 0 , 4 ) , X 1 , X 2 , ⋯ , X 15 X\sim N(0,4),X_1,X_2,\cdots,X_{15} X ∼ N ( 0 , 4 ) , X 1 , X 2 , ⋯ , X 15 Y = X 1 2 + X 2 2 + ⋯ + X 10 2 2 ( X 11 2 + ⋯ + X 15 2 )
Y = \frac {X^2_1 + X^2_2 +\cdots + X^2_{10}} {2(X^2_{11} + \cdots + X^2_{15})}
Y = 2 ( X 11 2 + ⋯ + X 15 2 ) X 1 2 + X 2 2 + ⋯ + X 10 2 设 1 4 S 1 2 = ( X 1 2 ) 2 + ⋯ + ( X 10 2 ) 2 ∼ χ 2 ( 10 ) 设 1 4 S 2 2 = ( X 11 2 ) 2 + ⋯ + ( X 15 2 ) 6 2 2 ∼ χ 2 ( 5 ) ∴ Y = X 1 2 + ⋯ + X 10 2 2 ( X 11 2 + ⋯ + X 15 2 ) = 1 4 S 1 2 / 10 1 4 S 2 2 / 5 ∼ F ( 10 , 5 )
设\frac 1 4 S_1^2 = (\frac {X_1} 2)^2 + \cdots + (\frac {X_{10}} 2)^2 \sim \chi^2(10)\\
设\frac 1 4 S_2^2 = (\frac {X_{11}} 2)^2 + \cdots + (\frac {X_{15}} 2)62^2 \sim \chi^2(5)\\
\therefore Y = \frac {X^2_1 + \cdots + X^2_{10}} {2(X^2_{11}+\cdots+X^2_{15})} = \frac {\frac 1 4 S^2_1 / 10} {\frac 1 4 S^2_2 / 5} \sim F(10,5)
设 4 1 S 1 2 = ( 2 X 1 ) 2 + ⋯ + ( 2 X 10 ) 2 ∼ χ 2 ( 10 ) 设 4 1 S 2 2 = ( 2 X 11 ) 2 + ⋯ + ( 2 X 15 ) 6 2 2 ∼ χ 2 ( 5 ) ∴ Y = 2 ( X 11 2 + ⋯ + X 15 2 ) X 1 2 + ⋯ + X 10 2 = 4 1 S 2 2 /5 4 1 S 1 2 /10 ∼ F ( 10 , 5 )
α \alpha α 定义 设x x x α ( 0 < α < 1 ) \alpha(0<\alpha<1) α ( 0 < α < 1 ) η 1 \eta_1 η 1
P ( X ≤ η 1 ) = α ,
\mathrm{P}(X\leq\eta_1)=\alpha,
P ( X ≤ η 1 ) = α ,
则称η 1 \eta_{1} η 1 α ( 0 < α < 1 ) \alpha(0<\alpha<1) α ( 0 < α < 1 ) η 2 \eta_{2} η 2
P ( X ≥ η 2 ) = α ,
\mathbb{P}(X\geq\eta_2)=\alpha,
P ( X ≥ η 2 ) = α ,
则称η 2 \eta_{2} η 2
正态总体的抽样分布
假设总体X 服从正态分布N( μ , σ 2 ) , ( X 1 , X 2 , ⋯ , X n ) (\mu,\sigma^2),(X_1,X_2,\cdots,X_n) ( μ , σ 2 ) , ( X 1 , X 2 , ⋯ , X n )
X ‾ = 1 n ∑ k = 1 n X k , S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ‾ ) 2 \overline{X}=\frac1n\sum_{k=1}^nX_k,\quad S^2=\frac1{n-1}\sum_{i=1}^n(X_i-\overline{X})^2 X = n 1 ∑ k = 1 n X k , S 2 = n − 1 1 ∑ i = 1 n ( X i − X ) 2 X ∼ N ( μ , σ 2 ) X\sim\mathbf{N}(\mu,\sigma^2) X ∼ N ( μ , σ 2 ) X ‾ ∼ N ( μ , σ 2 n ) . \overline{X}\sim\mathbf{N}(\mu,\frac{\sigma^2}n). X ∼ N ( μ , n σ 2 ) .
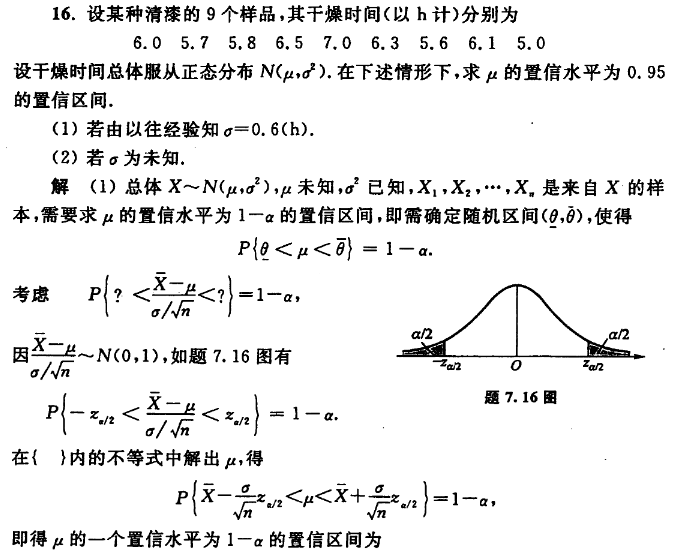
推论 若总体 X ∼ N ( μ , σ 2 ) ,则 X ‾ − μ σ 2 n ∼ N ( 0 , 1 ) . \text{推论 若总体}X\sim\mathbf{N}(\mu,\sigma^2)\text{,则}\frac{\overline{X}-\mu}{\sqrt{\frac{\sigma^2}n}}\sim\mathbf{N}(0,1). 推论 若总体 X ∼ N ( μ , σ 2 ) , 则 n σ 2 X − μ ∼ N ( 0 , 1 ) .
例题