
课时03
复习和补遗
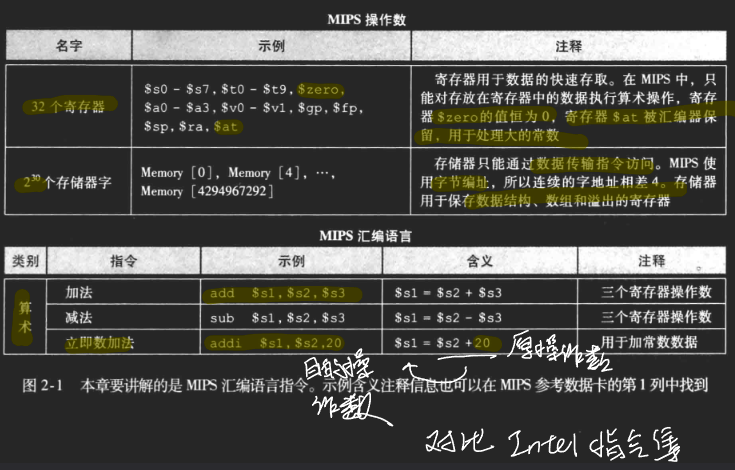
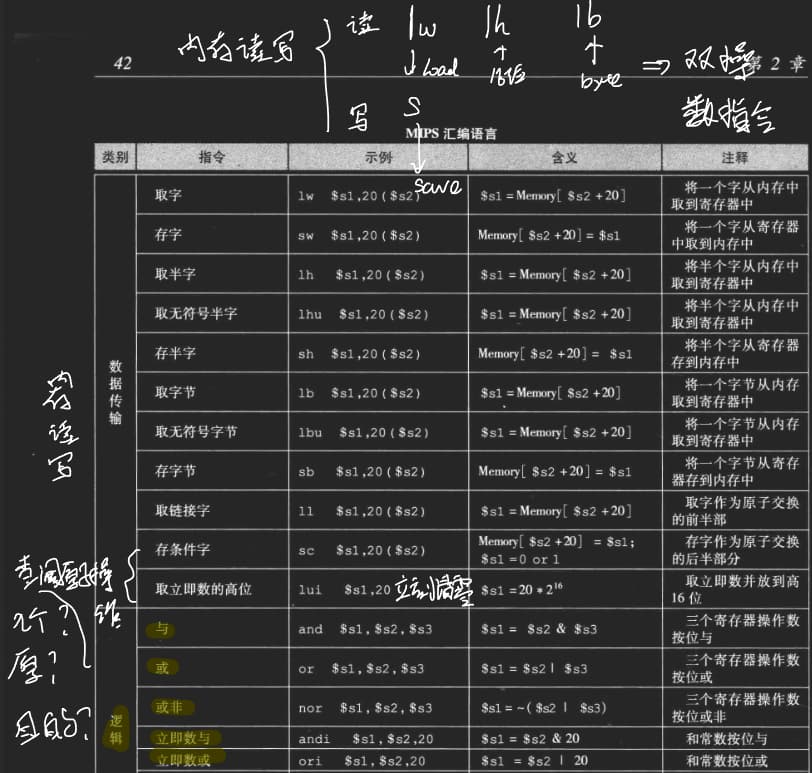
指令的格式,操作码(高6位) 和 操作数
0需要用0号寄存器表示这个立即数,所以常数不可能为0
留给常数的位数有限,一般很小,可正负有符号数,二进制补码
无符号数每一位都是有效数字
符号拓展 Sign Extension
有符号数,根据最高的符号位
e.g 4bit to 8bit
1111 -> 1111 1111
0111 -> 0000 0111
无符号数无论高位如何全部补0到需求的位数。
addi, extend immediate value
lb, lh: extend loaded byte/halfword
beq, bne: extend the displacement
instructions format
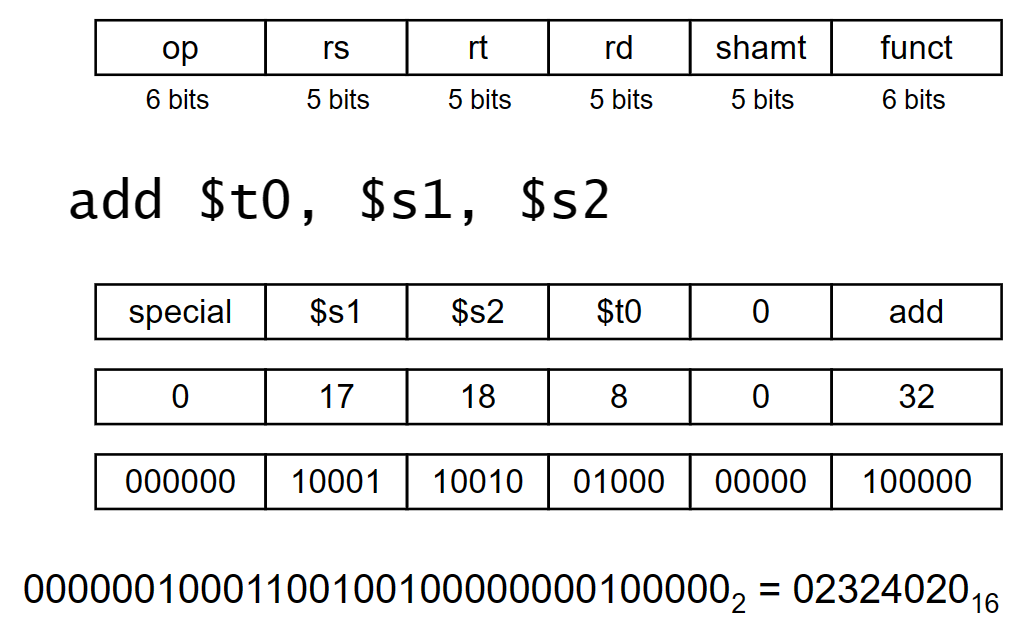
r-format instructions
| op | rs | rt | rd | shamt | funct |
|---|---|---|---|---|---|
| 6bits | 5bits | 5bits | 5bits | 5bits | 6bits |
在r-format中,三个oprand都是寄存器
rs:first source reg number
rt:second source reg number
rd destination reg number
shamt shiift aount 00000 移位,因为mips机器字长只有32位。
funct function code: 拓展码,也叫功能码。因此一共可以表示个指令了。
I-format
Only one oprand is immediate number and other two oprands are register
I-format也是一个有着3个操作数的指令。
| op | rs | rt | constand or adddress |
|---|---|---|---|
| 6bits | 5bits | 5bits | 16bits |
rt: dest or src register number
constant:
address: offset addded to base address in rs
和r-format相比,
higher 16 bits are same
lower 16bit is different
组成相似,这使得指令解析简单。
Design priinciple: good design demands good compromises
- Different formats complicate decoding, but allow 32-bit
instructions uniformly - Keep formats as similar as possible
logical operations
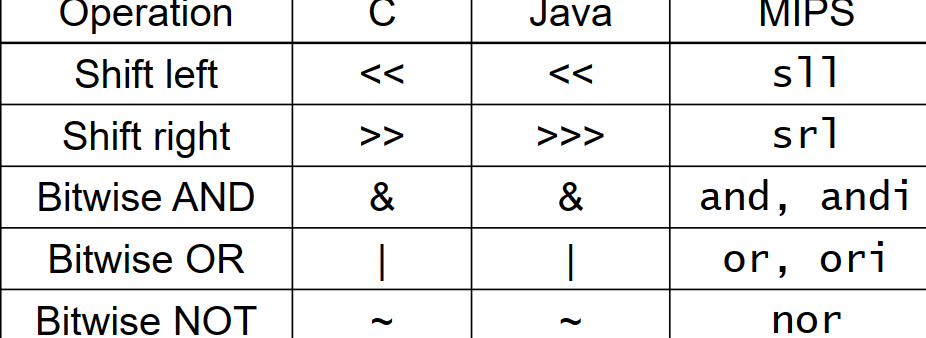
e.g.
op rs rt rd shamt funct
shamt : how many positions to shift
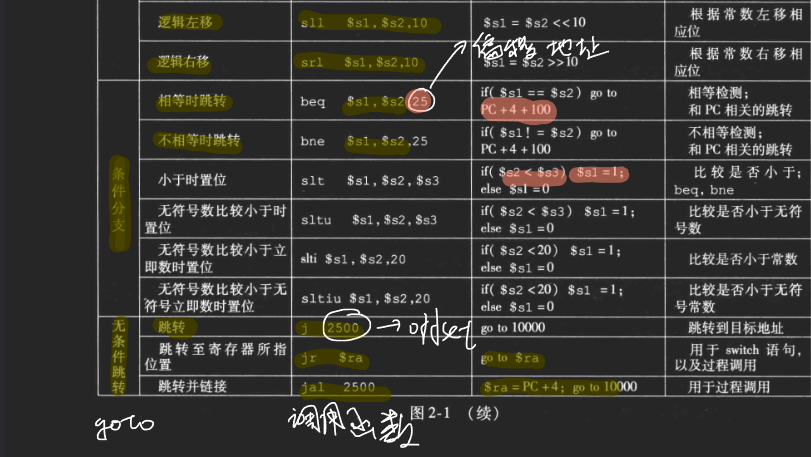
shift operations:
- shift left logical:
- shift left and fill with 0bits
- sll by i bits multiplies by 2^i
- shift right logical…
1001 1101
srl l:01001110
srav a:11001110
nor 3reg $t0 $t1 $zero
weile 和r型操作数做统一
条件分支指令 Conditional Operations
beq rs,rt,L1
if (rs == rt) branch to inst labeld L1
It is a I-fmt instruction, L1 here is an immediate number
bne
these two above is compiling if statements.
if (i == j) f = g + h;
else: f = g - h;
这里都是局部变量,所以用寄存器。
bne $s3,$s4,Else
add $s0,$s1,$s2
j Exit
Else: sub $s0,$s1,$s2
j L1 : unconitonal jump to instruction label L1
It belongs to J-fmt command
One opcode plus one oprand
Here is a compiling loop statement example.
while( save[i] == k ) i+= 1;
Loop: sll $t1, $t1 ,2 # 移位,x4,因为一个int占内存4个字节
add $t1, $t1, $s6 # 得到地址
lw $t0, 0($t1)
bne $t0, $s5, Exit
addi $s3, $s3, 1
j Loop
Exit: ...
lw 抽象一下那张矩形图,从下往上。
关于高级语言代码过编译器的优化tips
A basic block is a sequence of instructions
with
- No embedded branches (except at end)
- No branch targets (except at beginning)
- A compiler identifies basic blocks for optimization
- An advanced processor can accelerate execution of basic blocks
更多的条件分支操作
: r-fmt的 slt和i-fmt 的slti
slt rd, rs, rt
if (rs < rt) rd = 1; else rd = 0;
slti rt, rs, constant
if (rs < constant) rt = 1; else rt = 0;
? 先判断小于再判断等于
,调换的rs和rt
slt $t0, $s1, $s2 # if ($s1 < $s2)
bne $t0, $zero, L # branch to L
拓展阅读 Why not blt, bge, etc?
Hardware for <, ≥, … slower than =, ≠
Combining with branch involves more work per instruction, requiring a slower clock
All instructions penalized!
beq and bne are the common case
This is a good design compromise
case/switch statement
beq bne j jr
switch:
- 嵌套beq,a chain of if-elif
- 跳转表,jump address table/jump table类似你在oi中开大数组下标模拟哈希表一样。
switch(x):
case 0:
break;
…
case 200:
break;
假如只有9个标签,但是取case的最大数,需要200,用int类型就要开200*4bits空间。
非常耗费空间,适用于case多情况。
jr跳寄存器
Procedure Calling
j and jal
how to use 16bits to express 32bits address?
这就介绍到Program Counter了。
PC: program count程序计数器,无法被用户代码访问对特殊寄存器。
其值=下一条执行指令的地址,不是跳转(如存在)之后的值,而是刚刚执行的下一条指令。
存储程序程序到存储器中cpu从存储器取出所需要的指令。
相邻指令相距4个字节,pc每次自动+4bytes。
ps:存储器单位都是1个字节1个字节操作的。
所以转移地址怎么计算呢?
op 6bits + address 26bits
规定j和jal操作码只能转移到对齐地址。这个地址只能被4字节整除,也就是地址最低两位为0.。
在 MIPS 平台上,lh 读取一个半字时,存储器的地址必须是 2 的整数倍; lw 读取一个字时,存储器的地址必须是 4的整数倍; sd 写入一个双字时,存储器的地址必须是 8 的整数倍。倘若访存时,目标地址不对齐,则会引起异常,典型的是系统提示“总线错误”后,直接杀死进程。
所以,00 就需要不存了,只存高位。
所以现在16bits可以表示18bits的值。
bne beq : target address = PC + (offset* 4)
tips: pc has already incremented by 4 by this time
offset是有符号数,所以可以为负数。
j/ jal $PC_{31…28} $+ address(后26bits) * 4
例题p62
在最后的j loop中,
题节目中的地址是十进制,convert to bin进制,80024-》 31.。。28就是全0,
所以 所求的26bits数 * 4 == 80000(要跳转)
怎么跳的更远呢。
过程调用
- Placeparametersinregisters
- Transfer control to procedure
- Acquire storage for procedure
- Performprocedure’soperations
- Place result in register for caller
- Return to place of call
call
jal ProcedureLabel 起下列两个作用(call)
- pc赋值给ra (作为return address),Address of following instruction put in $ra
- PC(31-28)连接I * 4 赋值给PC. 这也是j操作码所做的。Jumps to target address
jr return: ra重新赋值给pc
做过程调用的第2和6步。
温习用到的reg
$a0 – $a3: arguments (reg’s 4-7)
$v0, $v1: result values (reg’s 2 and 3)
$sp: stack pointer (reg 29)
$ra: return address (reg 31)
叶子过程(即不会再调用其他过程)示例,
int leaf_exam(intg ,h ,i ,j) // a0 a1 a2 a3必定按顺序编号{
int f;
f= (g + h) - (i +j);
return f;
}
Arguments g, …, j in $a0, …, $a3
f in $s0 (hence, need to save $s0 on stack)
Result in $v0
leaf_example:
# Save $s0 on stack
addi $sp, $sp, -4
sw $s0, 0($sp)
# Procedure body
add $t0, $a0, $a1
add $t1, $a2, $a3
sub $s0, $t0, $t1
# Result
add $v0, $s0, $zero
# Restore $s0
lw $s0, 0($sp)
addi $sp, $sp, 4
# Return
jr $ra
非叶子过程示例,
Procedures that call other procedures
For nested call, caller needs to save on the
stack:
- Its return address
- Any arguments and temporaries needed after
the call
Restore from the stack after the call
这里示例递归法求阶乘。
C code:
int fact (int n)
{
if (n < 1) return 1;
else return n * fact(n - 1);
}
- Argument n in $a0
- Result in $v0
fact:
addi $sp, $sp, -8 # adjust stack for 2 items
sw $ra, 4($sp) # save return address
sw $a0, 0($sp) # save argument
slti $t0, $a0, 1 # test for n < 1
beq $t0, $zero, L1
addi $v0, $zero, 1 # if so, result is 1
addi $sp, $sp, 8 # pop 2 items from stack
jr $ra # and return
L1: addi $a0, $a0, -1 # else decrement n
jal fact # recursive call
lw $a0, 0($sp) # restore original n
lw $ra, 4($sp) # and return address
addi $sp, $sp, 8 # pop 2 items from stack
mul $v0, $a0, $v0 # multiply to get result
jr $ra # and return
其他的话
像c语言的函数内static变量,存储在内存中而不是寄存器。
另外,下周才布置作业。



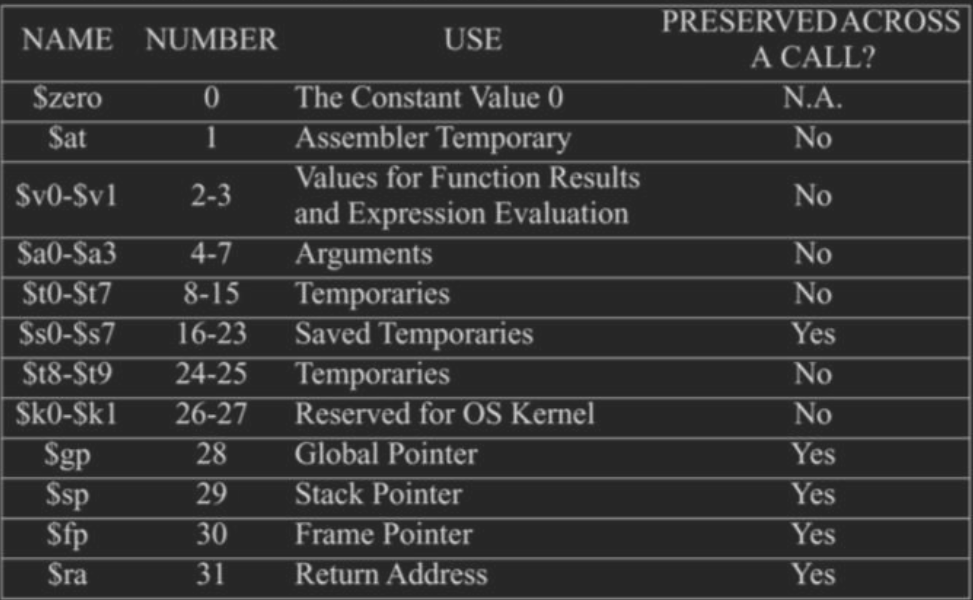 mips has a 32x32-bitRegiter file
mips has a 32x32-bitRegiter file

