
2023年7月31日星期一
2023年7月30日星期日
py 技巧
python部分其他功能
闭包
定义双层嵌套函数,内层函数可以访问外层函数的变量
将内存函数作为外层函数的返回,此内层函数就是闭包函数
优点,使用闭包可以让我们得到:
无需定义全局变量即可实现通过函数,持续的访问、修改某个值
闭包使用的变量的所用于在函数内,难以被错误的调用修改
缺点:
由于内部函数持续引用外部函数的值,所以会导致这一部分内存空间不被释放,一直占用内存
在闭包函数(内部函数中)想要修改外部函数的变量值
需要用nonlocal声明这个外部变量
# 让内部的函数依赖外部的变量
def outer(logo):
def inner(msg, is_modify=False):
# 如果要在闭包内部函数中修改外部函数的变量,只需要用Nonlocal关键字
if is_modify is True:
nonlocal logo
logo = "kirisame"
print(f"fixed{logo}:flexible{msg}")
return inner # 返回一个函数,并且这个函数可以接受一个参数,功能是打印一个字符串
fn1 = outer("touhou")
fn1("yoyomu")
outer("hakurei")("reimu")
fn1("marisa", True)
装饰器
装饰器其实也是一种闭包,其功能就是在不破坏目标函数原有的代码和功能的前提下,为目标函数增加新功能
def sleep():
import random
import time
print("Sleeping")
time.sleep(random.randint(1, 5))
# 现在希望给此函数增加功能,调用sleep前后各输出一句话
# 1.闭包写法
def outer(func):
def inner():
print("Advanced")
func()
print("awake")
return inner
exsleep = outer(sleep)
exsleep()
# 2.快捷写法,语法糖
"""
装饰器就是使用创建一个闭包函数,在闭包函数内调用目标函数
可以达到不改动目标函数的同时,增加额外的功能
"""
@outer
def study():
print("studying")
study() # 本质上调用了Inner()
设计模式
设计模式是一种编程套路,可以极大的方便程序的开发
最常见、最经典的设计模式,就是我们所学习的面向对象了
除了面向对象外,在编程中也有很多既定的套路可以方便开发,我们称之为设计模式
- 单例、工厂模式
- 建造者、责任链、状态、备忘录、解释器、访问者、观察者、中介、模板、代理模式
单例模式
单例模式就是对一个类,只获取其唯一的类实例对象,持续复用它
- 节省内存
- 节省创建对象的开销


工厂模式
当需要大量创建一个类的实例的时候,可以使用工厂模式。
即,从原生的使用类的构造去创建对象的形式迁移到,基于工厂提供的方法去创建对象的形式
class Person:
pass
class Worker(Person):
pass
class Student(Person):
pass
class Teacher(Person):
pass
worker = Worker()
stu = Student()
teacher = Teacher()
class Person:
pass
class Worker(Person):
pass
class Student(Person):
pass
class Teacher(Person):
pass
class Factory:
def get_person(self,p_type):
if p_type == 'w':
return Worker()
elif p_type =='s':
return Student0
else:
return Teacher()
factory = Factory()
worker = factory.get_person('w')
stu = factory.get_person('s')
teacher = factory.get_person('t')
使用工厂类的get_person()方法去创建具体的类对象
将对象的创建由使用原生类本身创建
转换到由特定的工厂方法来创建
优点:
- 大批量创建对象的时候有统一的入口,易于代码维护
- 当发生修改,仅修改工厂类的创建方法即可
- 符合现实世界的模式,即由工厂来制作产品(对象)
py多线程
现代操作系统比如MacOSX,UNIX,Linux,Windows等,都是支持“多任务”的操作系统
进程:就是一个程序,运行在系统之上,那么便称之这个程序为一个运行进程,并分配进程ID方便系统管理
线程:线程是归属于进程的,一个进程可以开启多个线程,执行不同的工作,是进程的实际工作最小单位
进程就好比一家公司,是操作系统对程序进行运行管理的单位
线程就好比公司的员工,进程可以有多个线程(员工)是进程实际的工作者
- 操作系统中可以运行多个进程,即多任务运行
- 一个进程内可以运行多个线程,即多线程运行
进程之间是内存隔离的,
即不同的进程拥有各自的内存空间。这就类似于不同的公司拥有不同的办公场所。
线程之间是内存共享的,线程是属于进程的,一个进程内的多个线程之间是共享这个进程所拥有的内存空间的。这就好比,公司员工之间是共享公司的办公场所。
并行执行
并行执行的意思指的是同一时间做不同的工作
进程之间就是并行执行的,操作系统可以同时运行好多程序,这些程序都是在并行执行
除了进程外线程其实也是可以并行执行的。
也就是比如一个Python程序, 其实是完全可以做到
- 一个线程在输出:你好
- 一个线程在输出: Hello
像这样一个程序在同一时间做两件乃至多件不同的事情,我们就称之为:多线程并行执行
Threading模块
import threading
thread_obj = threading.Thread([group [,target [, name [, args[,kwargs]]]]])
# group: 暂时无用,未来功能的预留参数
# target: 执行的目标任务名
# args: 以元组的方式给执行任务传参
#kwargs: 以字典方式给执行任务传参
# name: 线程名,一般不用设置
# 启动线程,让线程开始工作
thread_obj.start()
# 简单实例
import threading
import time
def sing():
while True:
print("1")
time.sleep(1)
def dance():
while True:
print("2")
time.sleep(1)
sing_thread = threading.Thread(target=sing)
dance_thread = threading.Thread(target=dance)
sing_thread.start()
dance_thread.start()
需要传参的话可以通过
- args参数通过元组(按参数顺序)的方式传参
- 或使用kwargs参数用字典的形式传参
def dance(msg:str):
while True:
print(msg)
time.sleep(1)
dance_thread = threading.Thread(target=dance,args=("x",))
dance_thread.start()
def dance(m1:str,m2:str):
while True:
print(m1,m2)
time.sleep(1)
dance_thread = threading.Thread(target=dance,kwargs={"m2":"456","m1":"123"})
dance_thread.start()
socket通信
socket(简称 套接字)是进程之间通信一个具,好比现实生活中的插座,所有的家用电器要想工作都是基于插座进行
进程之间想要进行网络通信需要socket。
Socket负责进程之间的网络数据传输,好比数据的搬运工
2个进程之间通过Socket进行相互通讯,就必须有服务端和客户端
Socket服务端:等待其它进程的连接、接受发来的消息、可以回复消息
Socket客户端:主动连接服务端、可以发送消息、可以接收回复
host
- 创建socket对象
import socket
socket_server = socket.socket()
- 绑定socket server到指定IP和地址
socket_server.bind((host:str, port:int)) # 传入一个有两个元素的元组
- 服务端开始监听端口
socker_server.listen(backlog)
# backlog为int整数,表示允许的连接数量,超出的会等待,可以不填,不填会自动设置一个合理值
- 接收客户端连接,获得连接对象
conn, address = socket_server.accept()
print(f"接收到客户端连接,连接来自: {address}")
# accept方法是阻塞方法,如果没有连接,会卡再当前这一行不向下执行代码
# accept返回的是一个二元元组,可以使用上述形式,用两个变量接收二元元组的2个元素
- 客户端连接后,通过recv方法,接收客户端发送的消息
while True:
data = conn.recv(1024).decode("uTF-8")
# recv方法的返回值是字节数组(Bytes),可以通过decode使用UTF-8解码为字符串
# recv方法的传参是buffsize,缓冲区大小,一般设置为1024即可
if data == 'exit':
break
print("接收到发送来的数据:",data)
#可以通过while True无限循环来持续和客户端进行数据交互
#可以通过判定客户端发来的特殊标记,如exit,来退出无限循环
- 通过conn(客户端当次连接对象)调用send方法可以回复消息
while True:
data = conn.recv(1024).decode("UTF-8")
if data == 'exit':
break
print("接收到发送来的数据:",data)
conn.send("你好呀哈哈哈”).encode("UTF-8)
- conn(客户端当次连接对象)和socket server对象调用close方法,关闭连接
py 爬虫
- requests网页下载库
- URL管理器
- HTML简介
- 网页解析器 beautiful soup
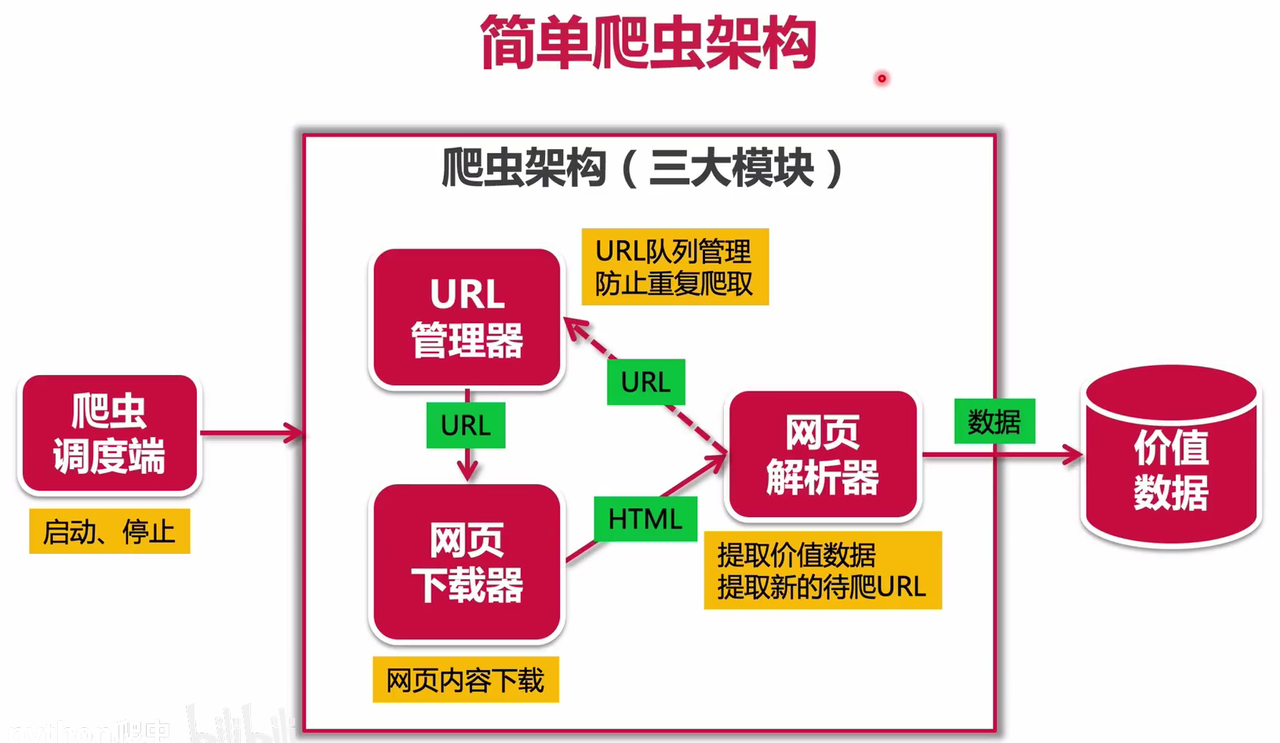
requests网页下载库
发送requests请求
reguests.get/post(url,params,data,headers,timeout,verify,allow redirects,cookies)
url:要下载的目标网页的URLparams:字典形式,设置URL后面的参数,比如?id=123&name=xiaomingdata:字典或者字符串,一般用于POST方法时提交数据headers:设置user-agent、refer等请求头timeout:超时时间,单位是秒verify:True/False,是否进行HTTPS证书验证,默认是,需要自己设置证书地址allow_redirects:True/False是否让requests做重定向处理,默认是cookies:附带本地的cookies数据
接受response响应
requests.get/post(url)
r.status_code:查看状态码,如果等于200代表请求成功r.encoding:可以查看当前编码,以及变更编码(重要!requests会根据Headers推测编码,推测不到则设置为ISO-8859-1可能导致乱码)r.text查看返回的网页内容r.headers:查看返回的HTTP的headersr.url:查看实际访问的URLr.content:以字节的方式返回内容,比如用于下载图片r.cookies:服务端要写入本地的cookies数据
注意事项
如果headers没有encoding信息,默认ISO-8859-1
中文网页可能出现乱码,查看text,在<header>标签中<meta \>的charset成员可能含有编码信息
可自行设定r.encoding成员
URL管理器
作用:对爬取URL进行管理,防止重复和循环爬取,支持新增URL和取出URL

见utils/url_manager.py
class UrlManager:
"""
URL管理器
"""
def __init__(self) -> None:
self.newUrls = set()
self.oldUrls = set()
pass
def AddUrl(self, url):
if url is None or len(url) == 0:
return # 不合格
# 判断url是否已经存在
if url in self.newUrls or url in self.oldUrls:
return
self.newUrls.add(url)
def AddUrls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.AddUrl(url)
pass
def GetUrl(self):
if self.HasNewUrl():
url = self.newUrls.pop()
self.oldUrls.add(url)
return url
else:
return None
def HasNewUrl(self):
return len(self.newUrls) > 0
HTML简介

网页解析器 beautiful soup
语法

见myBS.py
BeautifulSoup方法选择器find()方的使用
关于find()函数参数的一些tips
- 可以抓取存在某种标签的情形和存在标签匹配的情形
items = soup.find_all("div","class") - 可以部分匹配
<div>标签们中有两个数据<div class="craw_me marisa">和<div class="craw_me reimu">
执行
后,输出列表items = soup.find_all("div", class_="craw_me") print(items)[<div class="craw_me reimu">you craw reimu </div>, <div class="craw_me marisa">you craw marisa </div>]。即find()可以部分匹配
beautifulsoup获取有价值的信息
- view-source,未加载动态之前的源代码
- 右键-检查
Elements->浏览器展示真实看到的代码,如已经加载js
Network抓包- preserve log 跳转到新页面时保存原来log
- disable cache 防止从本地取数据
Doc: Headers的一些重要参数
Request Method Get/Post
Status Code 200请求成功
Content-Type 返回,可能是text/html 可能是json等。以及有编码如UTF-8
Cookie
User-Agent
实战
爬取静态网站
爬取epicmo的博文标题
blogtest.py
爬去文章博客全部文章列表

requests请求时附带cookie字典
import requests
cookies = {
"captchakey":"14a54079a1",
"captchaExpire":"1548852352"
}
r = requests.get(url, cookies=cookies)
正则表达式实现模糊匹配
r/R:非转义的原始字符串
与普通字符相比,其他相对特殊的字符,其中可能包含转义字符,即那些,反斜杠加上对应字母,表示对应的特殊含义的,比如最常见的”\n”表示换行,”\t”表示Tab等。而如果是以r开头,那么说明后面的字符,都是普通的字符了,即如果是“\n”那么表示一个反斜杠字符,一个字母n,而不是表示换行了。
以r开头的字符,常用于正则表达式,对应着re模块。
版权声明:本文为CSDN博主「抖腿大刘」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u010496169/article/details/70045895
url1 ="http://www.crazyant.net/123.html"
url2 ="http://www.crazyant.net/123.html#comments
url3 ="http://www.baidu.com'
import re
pattern = r'^http://www.crazyant.net/\d+\.html$'
print(re.match(pattern, url1)) # ok
print(re.match(pattern,url2)) # None
print(re.match(pattern,url3)) # None
filmreview
从url https://movie.douban.com/review/best/ 中获取热门评论共5页,包括评价电影,时间,文本内容。并将结果存在数据库中。
在这个案例中着重使用了user-agent简单破解网站的反爬机制,以及使用多个find来定位所需要的数据。以及一些sql的小知识。
北京天气
https://tianqi.2345.com/wea_history/54511.htm
涉及技术
- headers中设置user agent反爬机制
- 通过network抓包,payload中有所传参数,分析ajax的请求和参数
- 通过for循环请求不同的参数的数据
- 利用pandas实现excel的合并与保存
[pre]beautifulsoup抓取动态网页
(https://blog.51cto.com/u_15057841/3460666)
selenium实现关于动态网页的抓取
前提,selenium教程
本文过时信息注意
python3.0以后 selenuim.webdriver 库不在推荐使用find_element_by_接后缀的方法
现在使用find_element和find_elements方法,其中
-
通过webdriver对象的find_element(“属性名”,“属性值”)
- 我们要定位一个属性id,值为"wang"的元素
find_element('id','wang')- 我们要定位一个属性class,值为"plant"的元素
find_element('id',"plant") -
通过webdriver模块中的By,以指定方式定位元
导入模块:from selenium.webdriver.common.by import By
如:定位id为username,class_name为password,tag_name为input的元素from selenium.webdriver.common.by import By webdriver.find_element(By.ID,'username') webdriver.find_element(By.CLASS_NAME,'password') webdriver.find_element(By.TAG_NAME,'input')其实这种方法和第一种方法类似,因为By类中的ID,CLASS_NAME这些成员都是常量字符串,值就是’id’,‘class name’
-
find_element()和find_elements()的区别
find_element()的返回结果是一个WebElement对象,如果符合条件的有多个,默认返回找到的第一个,如果没有找到则抛出NoSuchElementException异常。find_elements()的返回结果是一个包含所有符合条件的WebElement对象的列表,如果未找到,则返回一个空列表。
如果要做到像soup那样的键值对部分匹配,需要用到xpath定位
xpath常用表达式
| 表达式 | 描述 | 举例 |
|---|---|---|
| nodename | 选取此节点的所有子节点 | form,选取form节点 |
| / | 从根节点开始选取,绝对定位 | /html/body/form/input,选取input节点 |
| // | 从符合条件的元素的开始,而不考虑它们的位置。相对定位 | //form/input,选取input节点form//input,选择form元素的后代的所有 input 元素 |
| . | 选取当前节点 | |
| … | 选取当前节点的父节点 | //input/.. |
| @ | 元素属性 | //form/input[@name],选取带有name属性的input节点;//input[@name=‘username’] ,选取所有name属性为username的input节点;//input[@*]选择有任何属性的input节点 |
| [] | 如果有多个元素,可以进行筛选 | /div[1]第一个(和传统排序方法不同);/div[last()]最后一个;/div[last()-1]倒数第二个 |
| * | 选择任何节点 | /form/*,选择form之后的所有节点 |
| | | 或者 | //form | //a,选择所有的input和a节点 |
| @属性名 | 选取属性 | //a[@id=“link1”]/@href,选取id为link1的a标签的href属性值(此方法在lxml可用) |
| text() | 获取文本内容 | //a[@id=“link1”]/text(),选取id为link1的a标签的文本内容(此方法在lxml可用) |
| contains() | 包含内容(模糊匹配) | //span[contains(text(), “Latest”)],选取文本内容包含“Latest”的span标签 |
css常用表达式
| 表达式 | 说明 | 举例 |
|---|---|---|
| #id | 通过id选择元素 | #username,选择id为username的元素 |
| .class | 通过类选择元素 | .container ,选择class为container的元素 |
| element | 通过元素名选择元素 | input,选择所有input元素 |
| [attribute] | 通过属性选择元素,选择具有attribute属性的元素 | |
| [attribute=value] | 通过属性选择元素 | [type=“password”],选择type属性为password的元素 |
| a:link,a:visited | 选择未被访问、已被访问过的元素 | |
| p:empty | 选择没有子元素的p元素 | |
| element>element | 选择父元素为 div 的所有input 元素 | div>input |
表达式实例
拿test.html举例,
# 绝对路径(层级关系)定位
# soup.find_all(xxx)[n].find(xxx)
data = edge.find_elements("xpath","/html/body/div")
data = edge.find_elements("xpath","/html/body/div[1]")
data = edge.find_elements(By.CSS_SELECTOR, "html>body>div") # 这种方法只能返回第一或者一个列表而不能div[2]这种返回指定序号
执行命令,可以得到一个列表,而在列表[0]又可以find_element
此外有意思的是
[0].text
‘段落\n百度\n疯狂的蚂蚁\n爱奇艺’
# 利用元素属性定位
# soup.find_all(class_=["xxx",...])
data = edge.find_elements(By.XPATH,"//div") # 返回列表
# 层级+元素属性定位
# soup.find_all("div",class_=["xxx",...])
data = edge.find_elements(By.XPATH,"//div[@nb='233']") # 完全匹配,返回列表,两个元素
data = edge.find_elements(By.XPATH, "//div[@class='craw_me reimu']") # 完全匹配,唯一
data = edge.find_elements(By.XPATH, "//div[contains(@class,'craw_me')]") # 部分包含
data = edge.find_elements(By.CSS_SELECTOR, "html>body>div[nb='233']") # 完全匹配,返回列表,两个元素
# 逻辑运算符定位
data = edge.find_elements(By.XPATH, "//div[contains(@class,'craw_me') and contains(@nb,'233')]")
表达式定位总结
XPath常用的定位方式:
-
元素属性,快速定位,唯一属性:
//*[@id="images"] -
层级与属性结合,解决没有属性问题:
//div[@id="images"]/a[1] -
属性与逻辑结合,解决多个属性重名问题:
//*[@id="su" and @class="bg s_btn" ]
注意,表达式里的下标是从1开始的。
绝对定位以/开头,依赖页面的元素的顺序和位置,相对定位以//开头,不依赖页面元素顺序和位置,根据条件进行匹配,优先使用相对定位。
学习XPath本质就是掌握各种表达式的技巧,除了上述说到方法外,还有一些特别的定位方式:
-
查找id属性的值包含"kw"的元素:
//*[contains(@id,'kw')] -
查找⽂本⾥包含"新闻"的元素:
//*[contains(text(),'新闻')] -
查找class属性中开始位置包含’s_form_wrapper’关键字的元素:
//*[starts-with(@class,'s_form_wrapper')] -
使⽤多个相对路径去定位⼀个元素⽤//分开:
//div[@class=‘formgroup’]//input[@id=‘user-message’] -
轴定位:
轴定位,使用::表示

查找id="head"元素后⾯标签名为input的第一个元素

//*[@id="head"]//following::input[1]
其次link定位和partial-link定位对于匹配text的效果也非常好,这里截取原blog相关内容
link 专门用来定位文本链接,假如要定位下面这一标签。
<div class="practice-box" data-v-04f46969="">加入!每日一练</div>
我们使用find_element_by_link_text 并指明标签内全部文本即可定位。
driver.find_element_by_link_text("加入!每日一练")
partial_link 翻译过来就是“部分链接”,对于有些文本很长,这时候就可以只指定部分文本即可定位,同样使用刚才的例子。
<div class="practice-box" data-v-04f46969="">加入!每日一练</div>
我们使用 find_element_by_partial_link_text 并指明标签内部分文本进行定位。
driver.find_element_by_partial_link_text("加入")
当然由于方法的过期,以上方法改为find_element(By.LINK_TEXT,“xxx”)
selenium搭配beautifulsoup
由于selenium的find方法不太熟悉,这里搭配beautifulsoup
selenium搭配beautifulsoup
版权声明:本文为CSDN博主「Java Punk」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
-
导入关键库
import time # time函数 import xlwt # 进行excel操作 import os.path # os读写 from bs4 import BeautifulSoup # 解析html的 from selenium import webdriver # selenium 驱动 from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys # 模仿键盘 from selenium.webdriver.support.wait import WebDriverWait # 导入等待类 from selenium.webdriver.support import expected_conditions as EC # 等待条件 -
Selenium 解析动态Html
原博客中采用了判断当前页面没有明显的元素用来判断拉到什么位置就是底部,所以我的规则是:一直循环,直到连续5次
Keys.PAGE_DOWN(下拉),<li>标签数量不再增加,就认为已经到底了。为了避免程序计算太快,每次下拉还停顿了0.2秒,实际效果不错。 -
Selenium 转 BeautifulSoup
根据小编的开发经验,selenium 很擅长模拟和测试,它动态加载的特性是 BeautifulSoup不 具备的。但是,对于取值操作,简单的还好,复杂点的比如:循环
- 标签这种操作,我还是觉得BeautifulSoup更方便。
在爬虫的世界里,大量有价值的数据都是循环展现的,比如:某排行榜,某商品列表等…所以,Selenium + BeautifulSoup的操作必不可少。
核心代码也非常简单,直接传入 Selenium 驱动 driver,用 page_source() 就可以啦。# 获取完整渲染的网页源代码 pageSource = driver.page_source soup = BeautifulSoup(pageSource, 'html.parser') soup.prettify() - 标签这种操作,我还是觉得BeautifulSoup更方便。
-
保存数据至excel
def saveData(datalist, savepath): print("—————————— save ——————————") book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 创建workbook对象 sheet = book.add_sheet(dataTime, cell_overwrite_ok=True) # 创建工作表。sheet页名为dataTime col = ("排名", "图片链接", "名称", "品牌", "指导价", "销量") for i in range(0, len(col)): sheet.write(0, i, col[i]) # 列名 for i in range(0, len(datalist)): # print("第%d条" %(i+1)) # 输出语句,用来测试 data = datalist[i] for j in range(0, len(col)): sheet.write(i+1, j, data[j]) # 数据 if os.path.exists(savepath): # 清空路径 os.remove(savepath) book.save(savepath) # 保存
另外,在做爬虫时,通常是不需要打开浏览器的,只需要使用浏览器的内核,因此可以使用Chrome的无头模式
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
option = webdriver.EdgeOptions()
option.add_experimental_option("detach", True)
option.add_argument("--headless")
浏览器窗口切换
作者:Dream丶Killer
链接:https://juejin.cn/post/7074779332819812389
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在很多时候我们都需要用到窗口切换,比如:当我们点击注册按钮时,它一般会打开一个新的标签页,但实际上代码并没有切换到最新页面中,这时你如果要定位注册页面的标签就会发现定位不到,这时就需要将实际窗口切换到最新打开的那个窗口。我们先获取当前各个窗口的句柄,这些信息的保存顺序是按照时间来的,最新打开的窗口放在数组的末尾,这时我们就可以定位到最新打开的那个窗口了。
# 获取打开的多个窗口句柄
windows = driver.window_handles
# 切换到当前最新打开的窗口
driver.switch_to.window(windows[-1])
| 方法 | 描述 |
|---|---|
send_keys() | 模拟输入指定内容 |
clear() | 清除文本内容 |
is_displayed() | 判断该元素是否可见 |
get_attribute() | 获取标签属性值 |
size | 返回元素的尺寸 |
text | 返回元素文本 |
鼠标和键盘
作者:Dream丶Killer
链接:https://juejin.cn/post/7074779332819812389
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在webdriver 中,鼠标操作都封装在ActionChains类中,常见方法如下:
| 方法 | 描述 |
|---|---|
click() | 单击左键 |
context_click() | 单击右键 |
double_click() | 双击 |
drag_and_drop() | 拖动 |
move_to_element() | 鼠标悬停 |
perform() | 执行所有ActionChains中存储的动作 |
单击左键
模拟完成单击鼠标左键的操作,一般点击进入子页面等会用到,左键不需要用到 ActionChains 。
# 定位搜索按钮
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')
# 执行单击操作
button.click()
单击右键
鼠标右击的操作与左击有很大不同,需要使用 ActionChains 。
from selenium.webdriver.common.action_chains import ActionChains
# 定位搜索按钮
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')
# 右键搜索按钮
ActionChains(driver).context_click(button).perform()
双击
模拟鼠标双击操作。
# 定位搜索按钮
button = driver.find_element_by_xpath('//*[@id="toolbar-search-button"]/span')
# 执行双击动作
ActionChains(driver).double_click(button).perform()
拖动
模拟鼠标拖动操作,该操作有两个必要参数,
- source:鼠标拖动的元素
- target:鼠标拖至并释放的目标元素
# 定位要拖动的元素
source = driver.find_element_by_xpath('xxx')
# 定位目标元素
target = driver.find_element_by_xpath('xxx')
# 执行拖动动作
ActionChains(driver).drag_and_drop(source, target).perform()
鼠标悬停
模拟悬停的作用一般是为了显示隐藏的下拉框,比如 CSDN 主页的收藏栏,我们看一下效果。
# 定位收藏栏
collect = driver.find_element_by_xpath('//*[@id="csdn-toolbar"]/div/div/div[3]/div/div[3]/a')
# 悬停至收藏标签处
ActionChains(driver).move_to_element(collect).perform()
键盘控制
webdriver 中 Keys 类几乎提供了键盘上的所有按键方法,我们可以使用 send_keys + Keys 实现输出键盘上的组合按键如 “Ctrl + C”、“Ctrl + V” 等。
from selenium.webdriver.common.keys import Keys
# 定位输入框并输入文本
driver.find_element_by_id('xxx').send_keys('Dream丶killer')
# 模拟回车键进行跳转(输入内容后)
driver.find_element_by_id('xxx').send_keys(Keys.ENTER)
# 使用 Backspace 来删除一个字符
driver.find_element_by_id('xxx').send_keys(Keys.BACK_SPACE)
# Ctrl + A 全选输入框中内容
driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'a')
# Ctrl + C 复制输入框中内容
driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'c')
# Ctrl + V 粘贴输入框中内容
driver.find_element_by_id('xxx').send_keys(Keys.CONTROL, 'v')
其他常见键盘操作:
| 操作 | 描述 |
|---|---|
Keys.F1 | F1键 |
Keys.SPACE | 空格 |
Keys.TAB | Tab键 |
Keys.ESCAPE | ESC键 |
Keys.ALT | Alt键 |
Keys.SHIFT | Shift键 |
Keys.ARROW_DOWN | 向下箭头 |
Keys.ARROW_LEFT | 向左箭头 |
Keys.ARROW_RIGHT | 向右箭头 |
Keys.ARROW_UP | 向上箭头 |
[pre]元素等待
[pre]弹窗处理
cookies操作
作者:Dream丶Killer
链接:https://juejin.cn/post/7074779332819812389
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
cookies 是识别用户登录与否的关键,爬虫中常常使用 selenium + requests 实现 cookie 持久化,即先用 selenium 模拟登陆获取 cookie ,再通过 requests 携带 cookie 进行请求。
webdriver 提供 cookies 的几种操作:读取、添加删除。
- get_cookies:以字典的形式返回当前会话中可见的 cookie 信息。
- get_cookie(name):返回 cookie 字典中 key == name 的 cookie 信息。
- add_cookie(cookie_dict):将 cookie 添加到当前会话中
- delete_cookie(name):删除指定名称的单个 cookie。
- delete_all_cookies():删除会话范围内的所有 cookie。
下面看一下简单的示例,演示了它们的用法。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://blog.csdn.net/")
# 输出所有cookie信息
print(driver.get_cookies())
cookie_dict = {
'domain': '.csdn.net',
'expiry': 1664765502,
'httpOnly': False,
'name': 'test',
'path': '/',
'secure': True,
'value': 'null'
}
# 添加cookie
driver.add_cookie(cookie_dict)
# 显示 name = 'test' 的cookie信息
print(driver.get_cookie('test'))
# 删除 name = 'test' 的cookie信息
driver.delete_cookie('test')
# 删除当前会话中的所有cookie
driver.delete_all_cookies()
其他参考教程
Python爬虫库xPath, BeautifulSoup, re, selenium的详细用法
实战:爬取pixiv某画师的所有图片
涉及技术:反爬,使用第三方反向代理,二进制读取,二进制存储
Python爬虫之如何玩转cookie(技巧篇)
python基本语法
python基本语法整合
记录了远古时期学习python基本语法和几个容器的笔记,大多数是代码附注释。可能比较适合从有c++语言基础学习python
python字符串
"""
字符串,以数据容器的视角
老字符串无法修改
"""
my_str = "Wo ai hakurei reimu"
value = my_str[3]
value = my_str[-2]
# my_str[2] = "1" err字符串无法修改
# index查找子字符串
pos1 = my_str.index("ai")
print(f"ai 's position is in {pos1}")
# replace(str1, str2)
# 将1子字符串全部删掉,换成2子字符串
# 注意返回值是一个新的字符串需要接受
my_str2 = my_str.replace("hakurei", "kirisame")
print(my_str2)
# split(分隔字符串)
# 类似strtok,按照指定的分隔字符串,将字符串划分为多个字符串,并存入列表对象中,
# 字符串本身不变,但是得到一个列表对象
my_list = my_str.split(" ")
print(my_list)
# 字符串规整 strip(str)
# 默认去除前后空格
my_str3 = " ite as d "
new_mystr = my_str3.strip()
print(new_mystr)
my_str3 = "112 ite as d 222"
new_mystr = my_str3.strip("12 ") # 1 / 2 / (空格)的所有子串
print(new_mystr)
# count
# len
python函数
# 多返回值,使用逗号隔开
def test_return_func():
return 1, 2
x, y = test_return_func()
print(f"multi return {x} {y}")
# 函数参数种类
# 根据使用方式的不同分为
# 位置参数 根据函数定义的参数位置(经常用的那种)
# 关键字参数 函数调用时通过"键=值"的形式,可以让函数更加清晰,消除了参数的顺序要求
def user_info(name, age, gender):
print(f"你的名字是{name},年龄是{age},性别是{gender}")
# 关键字传参(可以不按照顺序)
user_info(age=20, name="博丽灵梦", gender="girl")
# 可以和位置参数混用,但是位置参数必须在前,且匹配参数顺序
user_info("博丽灵梦", age=20, gender="girl")
# 缺省参数
# 类似c++参数都是有默认值的
# 同样,缺省项在定义时要放到最后面
def return_func2(name="博丽灵梦"):
print(f"{name}")
return_func2("雾雨魔理沙")
return_func2()
# 不定长(可变)参数
# 位置传递和关键字传递
# 位置传递:穿进的所有参数都会被args变量收集,他会根据穿进参数的位置合并为一个元组,args是元组类型
def user_info(*args): # 星号是关键字,表示args可以接受的参数数量是无限的
print(args)
user_info("博丽灵梦", "雾雨魔理沙")
# 关键字传递,两个星号,数量不受限,需要键=值的形式,并组成字典
def user_info(**kwargs):
print(kwargs)
user_info(name="hakurei", nick="miaow") # key不需要引号
# 函数作为参数传递
# 计算逻辑的传递
def cmp_main(func):
print(func(1, 5))
def cmp_func1(x, y):
return x < y
def cmp_func2(x, y):
return x > y
print("调用第一个")
cmp_main(cmp_func1)
print("调用第二个")
cmp_main(cmp_func2)
# lambda匿名函数
# 在函数的定义中
# def 关键字可以定义带有名称的函数
# lambda关键字,可以定义匿名函数 (无名称)
# 有名称的函数,可以基于名称重复使用
# 无名称的匿名函数,只可临时使用一次。
# 匿名函数定义
"""
匿名函数定义语法:
lambda 传入参数: 函数体(一行代码)
lambda 是关键字,表示定义匿名函数
传入参数表示匿名函数的形式参数,如:xy表示接收2个形式参数
函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
"""
print("尝试lambda函数")
cmp_main(lambda x, y: x > y) # 和c++相比,def能直接写进函数里面,所以py中的lambda函数用于临时用途就可以了
python列表
可以简单理解为stl中的vector容器,不过list具有混装的特性
"""
Some test for list container
容纳多个元素2**63 - 1
可以容纳不同类型的元素(混装)
数据是有序存储待(有下标序号)
允许重复数据存在
可以修改(增删改)
"""
# 1.1 查找某特定元素在列表中出现待第一个下标
a = list()
my_list = [1, 5, "8964"]
pos_1 = my_list.index(5)
print(pos_1)
# 1.2 不存在待值会报错
# pos_2 = my_list.index("xijingping")
# 2.1 修改下标值待值
my_list[0] = 7
print(f"after modify {my_list}")
# 3.1 插入到指定的下标位置
my_list.insert(1, "xi")
print(f"after insert{my_list}")
# 3.2 追加一个元素
my_list.append("so")
print(f"after append {my_list}")
# 3.3 追加一批元素
my_list.extend([1, 23])
print(f"after extend {my_list}")
# 4.1 del关键字,元素删除
my_list = [1, 5, "8964"]
del my_list[2]
print(my_list)
# 4.2 pop方法,移除并且接受
my_list = [1, 5, "8964"]
receive = my_list.pop(2)
print(f"{my_list},{receive}")
# 4.3 remove方法,移除第一个匹配项
my_list = [1, 5, "89", "64", "89"]
my_list.remove("89")
print(f"remove {my_list}")
# 4.4 clear 清空列表
my_list.clear()
print(my_list)
# 5.1 统计某个元素出现多少次count
my_list = [1, 2, 3, 4, 5, 1, 2, 1]
count = my_list.count(1)
print(count)
# 6.1 len(size)全部元素数量
print(f"size is {len(my_list)}")
# example
# num = 0
# age_list = [21, 25, 21, 23, 22, 20]
# print(f"序号{num},此时列表为{age_list}")
# num += 1
# num = 0
# age_list = [21, 25, 21, 23, 22, 20]
# age_list.append(31)
# print(f"序号{num},此时列表为{age_list}")
# num += 1
# age_list.extend([29, 33, 30])
# print(f"序号{num},此时列表为{age_list}")
# num += 1
# receive = age_list.pop(0)
# print(f"序号{num},此时列表为{age_list}->{receive}")
# num += 1
# receive = age_list.pop()
# print(f"序号{num},此时列表为{age_list}->{receive}")
# num += 1
# print(f"序号{num},此时列表为{age_list}->{age_list.index(31)}")
# 遍历
# while循环
index = 0
while index < len(my_list):
print(my_list[index])
index += 1
# for循环
for eke in my_list:
print(eke)
python元组
"""
元组
不可以被修改
可以封装多个、不同类型的元素在内
虽然元组本身不能修改,但是如果有一个元素是list,那么这个list可以修改
使用小括号定义
a = ()
a = turple()
"""
# 1 定义
my_turple = (1, 2, "123")
my_turple2 = ()
print(f"{type(my_turple2)} , {my_turple}")
## 特殊的,定义单个元素的元组对象时
my_turple3 = "123" # 这里自动格式化,加括号会自动消失,但即使加了括号也就是显示那个唯一的元素
# 不能修改my_turple = ()
print(f"{type(my_turple3)}")
print(f"{type(my_turple)}")
my_turple3 = ("123",)
# 单个元素元组加括号
print(f"{type(my_turple3)}")
# 其他方法也有index count len while for循环
# 虽然元组本身不能修改,但是如果有一个元素是list,那么这个list可以修改
tur = (1, 2, [1, 3])
print(tur)
tur[2][0] = "123"
print(tur)
python set
python中的dict底层是用哈希表实现的,类似unorderer_set
"""
set
去重处理,并且内容无序
使用花括号
空集合set()
"""
# 定义
my_set = {"2", "1", "我是灵梦"}
# my_set2 = {}
my_set2 = set()
print(f"{my_set} {type(my_set2)}")
# 不支持下标索引访问,所以序列就不包含set
# 可以修改
# .add添加新元素
my_set.add("雾雨魔理沙")
print(my_set)
my_set.add("雾雨魔理沙") # 会去重
print(my_set)
# .remove将指定元素从集合内删除
my_set.remove("1")
print(my_set)
# .pop随机取出一元素
# .clear清空
my_set.clear()
print(my_set is None) # false
# 取出两个元素的差集
# 集合1.difference(集合2) 得到一个新集合,集合1有但是集合2没有
# plus:消除差集,.difference_update
# 在集合1中消除元素以成为.difference(集合2),即删除与集合2相同的元素
# set1.union(set2)将集合1和集合2组合。返回新集合,1和2不变
# 统计集合元素数量,len()
# 遍历
# 不支持下标索引,不支持while,但支持for循环
my_set = {1, 2, 3}
for ele in my_set:
print(ele, end=",")
python dict
python中的dict底层是用哈希表实现的,类似unordered_map
为一个键值对应一个值
"""
字典:字->含义 key->value
使用花括号,存储元素是键值对
"""
my_dict = {"博丽灵梦": "th1", "雾雨魔理沙": "th2", "爱莲": "th3"}
# 定义空字典
my_dict2 = {}
my_dict2 = dict()
# 定义重复key字典
# 会被之后定义的元素覆盖
# 无序,没有下标索引
# 使用[key]
print(my_dict["博丽灵梦"])
# 新增元素
# 语法:
# 字典[key] = value,字典被修改,新增了元素
# 更新元素
# 语法:
# 字典[key] = value, 字典被修改,元素被更新
# 删除元素pop(key)返回key对应的value并删掉
# 清空元素clear
# 获取全部的key, dict.keys()->列表
# 遍历字典,
# 通过获取全部的key来for循环key
# 直接对字典进行for循环 for key in my_dict:
# 统计字典元素数量len()
# example
python 数据容器
# 这里是数据容器通用的方法
# len元素个数(键值对也是一个元素)
# max 最大元素(字典,最大value对应的key)
# min 最小元素
# 类型转换
# 容器转列表
my_list = [1, 2, 3, 4, 5]
my_turple = (1, 2, 3, 4, 5)
my_string = "12345"
my_set = {1, 2, 3, 4, 5}
my_dict = {"key1": 1, "key2": 2, "key3": 3} # 除了转字符串是键值对完整的形式,其他都是key字符串
print(list(my_list))
print(list(my_turple))
print(list(my_string))
print(list(my_set))
print(list(my_dict))
print(tuple(my_list))
print(tuple(my_turple))
print(tuple(my_string))
print(tuple(my_set))
print(tuple(my_dict))
print(str(my_turple))
print(str(my_list))
print(str(my_string))
print(str(my_set))
print(str(my_dict))
# set
# 无转dict方式
# 通用排序
# sorted(容器, reverse=False)
my_list = [3, 1, 2, 5, 4]
sorted_list = sorted(my_list)
print(sorted_list) # 排序结果会变成列表对象
sorted_list = sorted(my_list, reverse=True)
print(sorted_list)
同时需要注意的是,在遍历容器用for item in items:,这里的item不能修改只能访问,如果要修改可以用
for nu in range(len(items)):间接修改items[nu]
python 序列容器
# 数据容器(序列)的切片操作
# 序列:内容连续,有序,可使用下标索引,如列表,元组,字符串
# 切片:从一个序列中,取出一个子序列
# 语法:序列[起始下标:结束下标:步长]类似正则,但是冒号.每个空都能留空(到结束)
# 步长:取元素的间隔,如果是1则为1个1个取,2则为间隔1个取
# 如果步长为负数
my_list = ["hakurei reimu", "kirisame marisa", "izamu sakuya", "hunko youmu"]
print(
my_list[-1:0:-1] # range(unlike dot , ,)
) # ['hunko youmu', 'izamu sakuya', 'kirisame marisa'],右边逻辑上均为开区间(不包括)
# 切片操作不会影响序列本身,而是复制一个新的序列
my_str = "9876543210"
# 整体倒序,切片取出
result1 = my_str[::-1][4:7]
print(result1)
# 切片取出,然后反转
result2 = my_str[3:6][::-1]
print(result2)
# split分隔,replace
result3 = my_str.split("7")[1]
result3 = result3.split("3")[0]
print(result3[::-1])
python 模块
这个就类似于c++的多文件开发,但是与之不同,python的导包更方便,不用额外写makefile或者cmakelist
"""
什么是模块
Python 模块(Module),
是一个 Python 文件,以 .py 结尾
模块能定义函数,类和变量,模块里也能包含可执行的代码
模块的作用: python中有很多各种不同的模块,每一个模块都可以帮助我
们快速的实现一些功能,比如实现和时间相关的功能就可以使用time模块
我们可以认为一个模块就是一个工具包,每一个工具包中都有各种不同的
工具供我们使用进而实现各种不同的功能.
大白话:模块就是一个Python文件,里面有类、函数、变量等,我们可以
拿过来用(导入模块去使用)
"""
"""
模块的导入方式
模块在使用前需要先导入 导入的语法如下
[from 模块名] import [模块 类 变量 函数] [as 别名]
常用的组合形式如:
import模块名
from 模块名 import 类、变量、方法等
from 模块名import*
import 模块名as别名
from 模块名 import 功能名 as 别名
基本语法:
import 模块名
import 模块名1,模块名2
模块名.功能名()
案例:导入time模块
# 导入时间模块
import time
print("开始"
# 让程序睡眠1秒(阻塞)
time.sleep(1)
print("结束")
"""
import time
time.sleep(2)
"""
from 模块 import 功能名
功能名()
例如只用time模块的sleep方法,其他不用
"""
from time import sleep
sleep(1)
"""
设置别名
"""
from time import sleep as sl
print("xi")
sl(2)
print("gou")
"""
自定义模块和使用
了解__main__变量作用
Python中已经帮我们实现了很多的模块,不过有时候我们需要一些个性化的模块,这里就可以通过自定义模块实现,也就是自己制作一个模块
案例:新建一个Python文件,命名为my_modulel.py,并定义test函数
"""
import myexmodule
myexmodule.ex_kira("a")
myexmodule.ex_nya("hi")
# 同名from import的方法会是最后一个导入的方法
"""
__main__
在写模块时,可能会测试一些模块,
如exmodule.py中会有ex_kira("a")对模块进行测试
但我不希望在之后调用时出现
我们调用时的文件的__name__会被赋值为__main__
可用此判断是否是main文件
__all__
如果一个模块文件中有__all__ 变量,当使用from xxx import *导入时,只能导入这个列表中的元素
"""
from myexmodule import *
# 没有ex_waste 了
'''
python包
如果python模块过多,可包为一个包,帮助我们管理这些模块
什么是Python包
从物理上看,包就是一个文件夹,在该文件夹下包含了一个 __init__.py 文件,该文件夹可用于包含多个模块文件
从逻辑上看,包的本质依然是模块
'''
#创建一个包
#导入自定义的包中的模块,并使用
import my_package.my_module1
import my_package.my_module2
my_package.my_module1.info_print1()
my_package.my_module2.info_print2()
# from my_package import my_module1
# from my_package import my_module2
my_module1.info_print1()
#my_module2.info_print2()
from my_package.my_modulel import info_print1
from my_package.my_module2 import info_print2
info_print1()
info_print2()
"""
#通过__all__变量,控制import *
__init__.py 本来是空的,但是当想控制导入的模块时,__all__列表,元素是模块的名字
"""
"""
安装第三方包
pip
"""
from my_utils.file_util import *
from my_utils.str_util import *
str1 = "12345"
print(str_reserve(str1))
print(substr(str1, 1, 3))
print_file_info("./testfile2.txt") # here is main file's path
append_to_file("./testfile2.txt", "12345")
print_file_info("./testfile2.txt")
在本次实验中用到的两个py文件
# my_utils/file_util.py
__all__ = ["str_reserve", "substr"]
def str_reserve(s):
return s[-1::-1]
def substr(s, x, y):
return s[x:y]
# my_utils/str_util.py
__all__ = ["print_file_info", "append_to_file"]
def print_file_info(file_name):
f = None
try:
f = open(file_name, "r", encoding="utf-8")
print(f.read())
except:
print("This file is not existed")
finally:
if not f is None:
f.close
def append_to_file(file_name, data):
f = open(file_name, "a", encoding="utf-8")
f.write(data)
f.close()
# myexmodule.py
__all__ = ["ex_kira", "ex_nya"]
def ex_kira(_char):
print(f"kira~{_char}")
def ex_nya(_miaow):
for cnt in range(0, 3):
print(f"nya!{_miaow}")
# new test
if __name__ == "__main__":
ex_kira("test:kira")
ex_nya("test:nya")
def ex_waste():
return 1
python 文件
# 文件的编码
# 规则集合,内容和二进制相互转化的逻辑
# 打开关闭读写
# 文件的读取
# open 函数(打开或新建)
# name,mode, encoding
# mode= 只读,写入,追加 r w a模式后加一个b表示以二进制方式
# encoding = 'UTF-8'
import time
f = open("./testfile.txt", "r", encoding="UTF-8") # 此时的 f 是 open 函数的文件对象
# encoding 参数在函数定义中并不在第三位,因此需要按关键字传参
print(type(f))
"""
读操作方法
第一次read/readline会记录读到哪,下一次读操作会继续
文件对象.read(num)
num表示要从文件中读取的数据的长度,单位字符/字节,缺省表示读取文件中所有的数据
博丽灵梦喜欢魔理沙
博丽灵梦 喜欢魔理沙
Hakurei Reimu like Marisa
Haku rei Reimu like Marisa
"""
# print(f.read(4))
# print("-----")
# print(f.read())
"""
.readlines()
按照行的方式把整个文件中的内容进行一次性读取,并且返回一个列表,每一行的数据为一个元素(字符串)
封装到列表
"""
# content = f.readlines() # 带最后的\n。可能要使用字符串规整strip清除空白字符(不过之后都是读二进制就是了)
# print(content)
"""
readline()
一次读取一行
"""
# line1 = f.readline()
# line2 = f.readline()
# print(f"{line1}{line2}")
"""
for循环读取文件行,line最后一个回车,for一个最后回车
"""
for line in f:
print(f"{line}")
"""
文件关闭
f.close()
"""
f.close()
"""
with open 操作
通过在with open的语句块中对文件进行操作
可以在操作完成后自动关闭close文件,避免遗忘掉close方法
"""
with open("./testfile2.txt", "r") as f2:
my_tuple = f2.readlines()
print(my_tuple)
# time.sleep(20) python竟然是seconds为单位而不是mile seconds
# example
# 统计itheima数量
cnt = 0
f = open("./testfile3.txt", "r", encoding="UTF-8")
for line in f:
cnt += line.count("itheima")
print(f"字符串itheima共出现{cnt}次")
f.close()
# 文件写入操作
# 打开文件
# 文件写入f.write("hello world")
# 内容刷新f.flush()
"""
直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
当调用flush的时候,内容会真正写入文件
这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
"""
f = open("./testfile4.txt", "w", encoding="utf-8")
f.write("HelloWorld")
f.flush()
# 文件的追加 a mode
"""
文件夹相关
import os
my_list = os.listdir(".") # 打印所有文件和文件夹
print(my_list)
os.chdir('myh_utils')# 切换当前工作目录
"""
python 异常
"""
当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的“异常”
也就是我们常说的BUG
"""
"""
基本捕获
try:
可能发生错误的代码
except:
如果出现异常执行的代码
"""
try:
f = open("./missingfile.txt", "r", encoding="utf-8")
except:
print("missing file,改为w模式打开")
f = open("./missingfile.txt", "w")
"""
捕获指定异常
try:
可能异常代码
except 异常类型:
"""
try:
a += 1
except NameError as e: # 只捕获NameError异常
print(f"name error->{e}")
"""
捕获多个类型异常
或,一旦出现则跳出
当捕获多个异常时,可以把要捕获的异常类型的名字,放到except 后,并使用元组的方式进行书写
try:
print(1/0)
except(NameError, ZeroDivisionError
print('ZeroDivision错误...')
"""
"""
捕获所有异常
"""
try:
1 / 0
b += 1
open("aasd.txt", "r")
except Exception as e:
print(type(e))
else:
# 没有异常执行
print("no err")
finally:
# 有无异常都要执行
print("finally")
# 异常的传递性
def func1():
print("func1 开始执行")
num = 1 / 0
# 肯定有异常,除以0的异常
print("func1 结束执行")
# 定义一个无异常的方法,调用上面的方法
def func2():
print("func2 开始执行")
func1()
print("func2 结束执行")
# 定义一个方法,调用上面的方法
def main():
try:
func2()
except Exception as e:
print(f"出现异常了,异常的信息是: {e}")
main()
除此之外,我也经常使用raise Exception("出了什么错")来手动报错

